kafka에 Message를 발행(publish)하는 reactor.kafka.sender.KafkaSener
카프카의 Message를 소비(consume)하는 reactor.kafka.reciver.KafkaReceiver
Publish(KafkaSener)
- Reactive Kafka Sender
-
Kafka로 보내는 메시지는 KafkaSender 클래스를 이용해서 보낸다. Sender는 Thread-Safe하며, 여러 스레드에 공유해 처리량을 끌어 올릴 수 있다. KafkaSender는 kafka로 Message를 전송할 때 사용하는 KafkaProducer와 하나로 연결된다.
- KafkaProducer: Kafaka Topic(=Message) 를 Produce(=Send) 구현체
- KafkaSender는 SenderOptions<Key, Value> 인스턴스로 만든다.
- 여기서 key와 value는 KafkaSender를 통해서 생성되는 producer records의 타입을 가리킨다.
- Kafka의 Message는 Producer records의 형태로 작성되고 key와 value를 갖는다.
- Example Code, Create KafkaSender Instance
fun kafkaSender(): KafkaSender<String, CovidSearchLinkDetail> { val kafkaProducerConfiguration: HashMap<String, Any> = hashMapOf( ProducerConfig.BOOTSTRAP_SERVERS_CONFIG to kafkaProperties.bootstrapServers, ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG to StringSerializer::class.java, ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG to JsonSerializer<CovidSearchLinkDetail>()::class.java ) val senderOption: SenderOptions<String, CovidSearchLinkDetail> = SenderOptions.create(kafkaProducerConfiguration) return KafkaSender.create(senderOption) } -
KafkaProducerConfig: Kafaka Topic(=Message) 를 Publish(=Send) 하는 설정 클래스
-
Subscribe(KafkaReceiver)
-
Reactive Kafka Recevier
- reactor.kafka.receiver.KafkaReceiver<K, V>
- reative receiver를 이용하여 Kafka Broker에 저장된 메세지를 consume(소비)한다. KafkaReceiver 인스턴스는 KafkaConsumer의 단일 인스턴스와 연결된다. 기반이 되는 KafkaConsumer는 멀티 스레드 방식의 동시성 접근이 제한되기 때문에 Thread-Safe하지 않다.
- ReceiverOptions<K, V>
- ReceiverOptions 인스턴스를 이용해서 Receiver를 생성한다. Receiver 인스턴스가 생성된 후, ReceiverOptions에 변경된 내용은 KafkaReceiver에서 사용되지 않는다. 변경된 사항을 적용하려면 Receiver 인스턴스를 재생성해야 한다.
KafkaReceiver<K, V>, ReceiverOptions<K, V>의 제네릭 타입은 Receiver로 소비할 Consumer Record의 Key, Value 타입이다. 그렇기 때문에 둘의 제네릭 타입은 동일해야 맞다.
[JAVA - Example]
public class KafkaConsumerConfig { private final KafkaProperties kafkaProperties; // `topicName`만 Consume하는 KafkaReceiver를 위한 카프카 설정을 // ReceiverOptions에 설정 후, #create(options)를 호출하면 // inbound message를 소비할 수 있는 KafkaReceiver Instance를 리턴한다. // KafkaReceiver Instance가 생성되는 시점은 즉시가 아닌 Lazy Create로 처리된다. // 생성되는 시점은 inbound flux가 subscribe를 시작하는 시점이다. public KafkaReceiver<String, String> kafkaReceiver(String topicName) { ReceiverOptions<String, String> options = ReceiverOptions.<String, String>create( kafkaProperties.buildConsumerProperties(null) ) .subscription(Set.of(topicName)) .addAssignListener((consumer) -> log.info("onPartitionsAssigned {}", consumer)) .addRevokeListener((consumer) -> log.info("onPartitionsRevoked {}", consumer)); return KafkaReceiver.create(options); } } @Slf4j @RequiredArgsConstructor @ReactiveKafkaListener(topic = "test") public class TradeListener { private final KafkaConsumerConfig kafkaConsumerConfig; public void subscribe(String topicName) { // #receive()를 호출함으로써 KafkaReceiver는 inbound kafka flux를 // Consume할 준비가 완료된다. kafkaConsumerConfig.kafkaReceiver(topicName).receive() .subscribe(stringStringReceiverRecord -> { // subscribe하는 시점에 KafkaRecevier 인스턴스가 생성되고 // inbound Flux Message가 ReceiverRecord 타입으로 넘어온다. log.info("Received Records => {}", stringStringReceiverRecord); }); } }[Kotlin]
@Component class KafkaConsumerConfig(val kafkaProperties: KafkaProperties) { fun kafkaReceiver(topicName: String, groupId: String? = null, partitionNo: Int = 1) : KafkaReceiver<String, CovidSearchLinkDetail> { // 1. KafkaConsumer에게 제공할 Properties를 지정한다. val kafkaConsumerConfig: Map<String, Any> = mapOf( ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG to kafkaProperties.bootstrapServers, ConsumerConfig.GROUP_ID_CONFIG to "test-consumer-group", ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG to StringDeserializer::class.java, ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG to JsonDeserializer<CovidSearchLinkDetail>( CovidSearchLinkDetail::class.java ), JsonDeserializer.VALUE_DEFAULT_TYPE to "com.example.demo.covid.CovidSearchLinkDetail", JsonDeserializer.USE_TYPE_INFO_HEADERS to false, JsonDeserializer.TRUSTED_PACKAGES to "*", ) // 2. 위에서 정의한 Properties를 이용해서 receiverOptions 인스턴스 생성한다. val receiverOptions = ReceiverOptions.create<String, CovidSearchLinkDetail>(kafkaConsumerConfig) // 3. ReceiverOptions객체를 이용해서 KafkaReceiver 인스턴스를 생성한다. return KafkaReceiver.create(receiverOptions) } } - reactor.kafka.receiver.KafkaReceiver<K, V>
Apache Kafka: Architecture, Real-Time CDC, and Python Integration
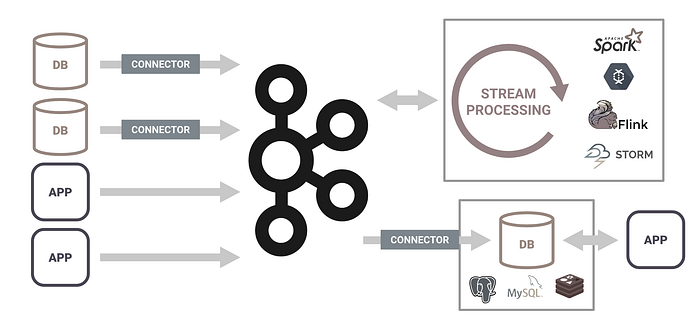
Apache Kafka is a distributed streaming platform that has gained significant popularity for its ability to handle high-throughput, fault-tolerant messaging among applications and systems. At its core, Kafka is designed to provide durable storage and stream processing capabilities, making it an ideal choice for building real-time streaming data pipelines and applications. This article will delve into the architecture of Kafka, its key components, and how to interact with Kafka using Python.
∘ Brokers
∘ Interacting with Kafka using Python
∘ Consuming Messages from Kafka
∘ Purpose of Dead Letter Queues
∘ Caching Strategies with Kafka
∘ 2.Kafka Streams State Stores
∘ 3.Interactive Queries in Kafka Streams
∘ Considerations for Caching with Kafka
· Example: Using Kafka Streams State Store for Caching
· Consuming Messages and Caching Results
∘ Partitioning in Apache Kafka
∘ Partitioning in Distributed File Systems
∘ Challenges and Considerations
∘ CDC Data from Kafka with Python
∘ Consuming CDC Data from Kafka with Python
∘ Using confluent-kafka-python
∘ Notes
Kafka Architecture Overview
https://miro.medium.com/v2/0*z5e9GMyQ9R-RFbJ2
The architecture of Apache Kafka is built around a few core concepts: producers, consumers, brokers, topics, partitions, and the ZooKeeper coordination system. Understanding these components is crucial to leveraging Kafka effectively.
Topics and Partitions
- Topics: The basic way Kafka manages data is through topics. A topic is a category or feed name to which records are published by producers.
- Partitions: Each topic can be split into multiple partitions. Partitions allow the data for a topic to be parallelized, as each partition can be placed on a different server, and multiple partitions can be consumed in parallel.
Producers and Consumers
- Producers: Producers are applications that publish (write) messages to Kafka topics. They can choose which topic (and optionally, which partition within a topic) to send messages to.
- Consumers: Consumers read messages from topics. They can subscribe to one or more topics and consume messages in a sequence from the partitions.
Brokers
- Brokers: A Kafka cluster consists of one or more servers known as brokers. Brokers are responsible for maintaining published data. Each broker can handle terabytes of messages without impacting performance.
ZooKeeper
- ZooKeeper: Kafka uses ZooKeeper to manage and coordinate the Kafka brokers. ZooKeeper is used to elect leaders among the brokers, manage service discovery for brokers to find one another, and perform other cluster management activities.
Kafka’s Distributed Nature
Kafka’s architecture is inherently distributed. This design allows Kafka to be highly available and scalable. You can add more brokers to a Kafka cluster to increase its capacity and fault tolerance. Data is replicated across multiple brokers to prevent data loss in the case of a broker failure.
https://miro.medium.com/v2/0*Y60EovrnihBBsZ7B
Kafka Streams and Connect
- Kafka Streams: A client library for building applications and microservices, where the input and output data are stored in Kafka clusters. It lets you process and analyze data stored in Kafka with ease.
- Kafka Connect: A tool for streaming data between Kafka and other systems in a scalable and reliable way. It provides reusable producers and consumers for connecting Kafka to external systems such as databases, key-value stores, search indexes, and file systems.
Handling Changes and State
- Offsets for Tracking Progress: Kafka uses offsets to track the position of consumers in a partition. Consumers commit their offset as they process messages, which Kafka uses to know which messages have been successfully processed. This allows consumers to restart from the last committed offset, ensuring no messages are missed or duplicated under normal operation, thus handling changes in the consumer state gracefully.
- Log Compaction for State Changes: Kafka offers a log compaction feature that ensures the retention of only the last known value for each key within a partition. This is particularly useful for maintaining the latest state of an entity. When log compaction is enabled, Kafka periodically compacts the log by removing older records with the same key, leaving only the most recent update for each key. This feature is essential for use cases where only the latest state is relevant, such as in event sourcing or maintaining materialized views.
- Replication for Fault Tolerance: Kafka replicates partitions across multiple brokers to ensure fault tolerance. Each partition has one leader and zero or more follower replicas. All writes and reads go through the leader replica to ensure consistency. If the leader fails, one of the followers can be promoted to be the new leader, ensuring high availability. Replication ensures that message order and changes are preserved even in the event of broker failures.
- Transactions for Atomic Changes: Kafka supports transactions, allowing producers to write multiple messages across partitions atomically. This means either all messages in the transaction are visible to consumers or none are. Transactions are crucial for ensuring consistency when a single logical change involves multiple messages across different partitions.
Understanding Offsets
https://miro.medium.com/v2/0*xUDOJWtIpo-Ax1Wh
Here are some key points about offsets in Kafka:
- Sequential and Immutable: Offsets are sequential. When a new message is produced to a partition, it gets the next available offset. This sequence ensures that the order of messages is maintained within a partition. Messages are immutable once written, and their offsets do not change.
- Partition Scope: Offsets are scoped to a partition; this means that each partition has its own sequence of offsets starting from zero. Therefore, a message in Kafka can be uniquely identified by a combination of its topic name, partition number, and offset within that partition.
- Consumer Tracking: Kafka consumers use offsets to track their position (i.e., progress) within a partition. When a consumer reads a message, it advances its offset to point to the next message it expects to read. This mechanism allows consumers to resume reading from where they left off, even after restarts or failures.
- Committing Offsets: Consumers periodically commit their offsets back to Kafka (or to an external store). This committed offset represents the consumer’s current position within the partition and ensures that the consumer does not reprocess messages it has already consumed, providing at least once processing semantics.
- Offset Retention: Kafka retains messages for a configurable period, not based on the number of messages or their offsets. Once a message expires (based on retention policies), it is eligible for deletion, and its storage space can be reclaimed. However, the offset sequence continues from the last value; it does not reset or change because of message deletion.
Practical Implications
- Message Ordering: Kafka guarantees the order of messages only within a partition, not across partitions. Consumers can rely on this order when processing messages.
- Scalability and Parallelism: By dividing topics into partitions and using offsets within each partition, Kafka allows for scalable and parallel consumption. Different consumers (or consumer groups) can read from different partitions independently at their own pace.
- Fault Tolerance: The use of offsets, combined with Kafka’s replication features, ensures that messages can be reliably processed even in the event of consumer failure. Consumers can pick up processing from the last committed offset.
- Custom Processing Logic: Advanced users can manipulate offsets for custom processing needs, such as replaying messages, skipping messages, or implementing exactly-once processing semantics in conjunction with Kafka’s transactional features.
In summary, offsets are a fundamental concept in Kafka that enables efficient, ordered, and reliable message processing in distributed systems. They facilitate Kafka’s high-throughput capabilities while supporting consumer scalability and fault-tolerant design.

Interacting with Kafka using Python
Python developers can interact with Kafka through the confluent-kafka-python library or the kafka-python library. Both provide comprehensive tools to produce and consume messages from a Kafka cluster.
Installation